Updated 7/30/15
Googlebot Cannot Access CSS and JS Files
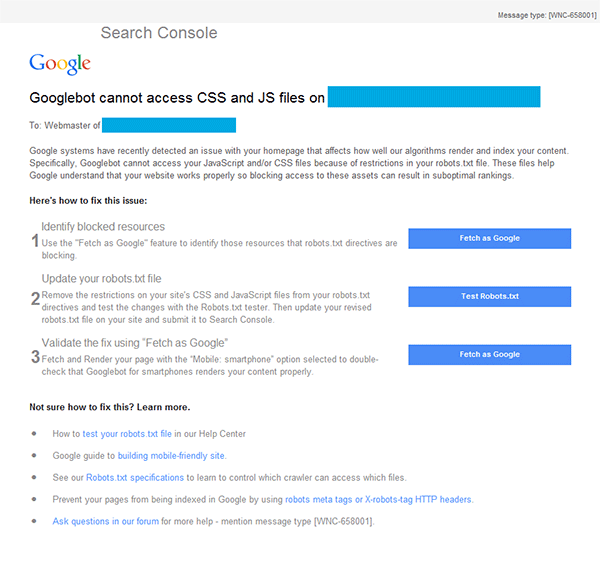
Beginning on 7/27/15 Google started sending email notifications to site managers via the Google Search Console (Webmaster Tools). These emails stated that:
“Google systems have recently detected an issue with your homepage that affects how well our algorithms render and index your content. Specifically, Googlebot cannot access your JavaScript and/or CSS files because of restrictions in your robots.txt file. These files help Google understand that your website works properly so blocking access to these assets can result in suboptimal rankings.”
In general terms Google has noted that some CSS or Javascript needed for rendering the page has been excluded from their eyes. Google has mentioned this on several occasions, for instance Matt Cutts mentions it here back in 2012:
Likewise, it was discussed in the Google Webmaster Central post “Updating Our Technical Webmaster Guildlines” last fall, and is covered again as part of the Webmaster Guidelines:
“To help Google fully understand your site’s contents, allow all of your site’s assets, such as CSS and JavaScript files, to be crawled.”
A final step, prior to the recent spat of email notifications, was the addition of the “Fetch and Render” function to the Google Search Console. It allows webmasters to see how a page renders for Googlebot on desktop/laptops, smartphones or feature phones, as well as a list of any resources (such as CSS and Javascript files) Googlebot is blocked from crawling or unable to crawl temporarily.
Fetch as Google/Fetch and Render
In Google Search Console under Crawl → Fetch as Google are tools allowing you to see what code Googlebot fetches for a page, how it renders for the bot and finally if any resources were missing or unable to be retrieved.
In the case of one site that received the email notification, Google listed only two images from a WordPress theme as ‘Temporarily Unreachable’.
In a second case, four external scripts were listed as blocked. One from createsend.com (Campaign Monitor), two from doubleclick.net and one from google.com/uds.
A third case showed two CSS files in the WordPress theme folder and a similar .less file were ‘Temporarily Unreachable’.
A fourth case showed one .less file in WordPress theme folder and a dozen images (2x Retina images) as ‘Temporarily Unreachable’.
You can see the diversity of apparent issues. Many others have reported similarly widespread files being returned for their own homepages when using this tool.
Blocked Resources
The Google Search Console also offers information on any blocked resources that “can impair the indexing of your webpages” under Google Index → Blocked Resources.
Of the four sites mentioned above only one had any indication of a blocked resource in this section (the external Campaign Monitor file). That file has little bearing on the rendering of the site either for desktop or smartphones.
The Robot.txt File
Many sites contain a robots.txt file in its web root, for example:
http://yourdomain.com/robots.txt
This file can contain various recommendations for search engines regarding which files to index and which to disallow. Note: these are generally considered as recommendations by the search engines, not absolute directives. There are many legitimate uses for the robots.txt files.
In the case of our example sites above, the robots.txt file for each read:
User-agent: *
Disallow: /wp-admin/
This is very common configuration for a WordPress site, requesting search engines not crawl or index the WordPress admin directory (/wp-admin/). It is not particularly restrictive.
Robots.txt Tester
If your robots.txt file is more involved, or seems to be blocking locations containing the CSS or Javascript files that are listed under Blocked Resources or mentioned under Fetch as Google, you should try using the robots.txt Tester under Crawl in the Google Search Console.
The tool will highlight any errors or warnings found in your robots.txt file.
In our case none of the four sites above showed any errors or warnings using this tool. This is not surprising given the paucity of the robots.txt file.
So What Do I Do?
Option 1: Trim Down Your Robots.txt File
If you have a more complex robots.txt file, for example something like:
User-agent: *
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /yomama/
…you should consider trimming it down to the essentials if possible. This of course requires some knowledge of which assets truly need to be blocked and which can slip by (at least for now). Generally speaking, if it’s a publicly accessible directory or file, or if the directory is listed in one of the alerts given by the Fetch as Google or Blocked Resources tools in Google Search Console, try removing it from the robots.txt file and retesting using Fetch and Render.
NOTE: If Fetch and Render shows a block to an external resource (one not on your site), you can safely ignore it.
Option 2: Allowing Additional Access via Robots.txt
a) You could remove the robot.txt file completely. Perhaps not the best solution unless you have no other option.
b) Use a “blank” robot.txt file:
User-agent: *
Disallow:
The above allows all access.
Please do not use:
User-agent: *
Disallow: /
…which will block all access to the site for bots following the rule.
c) The robots.txt file can be used to allow additional access, in this case to .js, .css and various images file types:
User-agent: *
Disallow: /wp-admin/
Allow: /*.js*
Allow: /*.css*
Allow: /*.png*
Allow: /*.gif*
Allow: /*.jpg*
The “Allow:” instruction tells a bot that it is okay to index a file in a directory that has been “Disallowed” by other instructions. In this case .js and four other file types would be allowed even within /wp-admin/.
The use of wildcards * in the Allow: directives matches any filename as well as any version numbers appended to end of the filename.
This seems like a pretty rough hack, but again if nothing else works, you might consider it.
Other Options
You can always do nothing for a spell and see how it all settles out in the coming weeks. If your only issues reported by Fetch as Google for both desktop and smartphone are marked ‘Temporarily Unreachable’, the error may resolve itself. You can check whether those files are available in your browser, or in a browser emulating a mobile device (Chrome allows for this in the Developer Tools console).
Otherwise, check back here and we will update this post as options reveal themselves.
Have a question? Leave it for us in the comments below.
Bonne Chance!